
Reasoning with Language Model is Planning with World Model
Github: https://github.com/maitrix-org/llm-reasoners
Motivation
LLMs struggle to generate action plans to achieve given goals in an environment, or performing complex logical reasoning, due to the lack of an internal world model to predict the world state (e.g., environment status, intermediate variable values) and simulate long-term outcomes of actions. And this paper present a LLM reasoning framework (Reasoning via Planning, RAP), repurposing the LLM as both a world model and a reasoning agent, and incorporates a principled planning algorithm based on Monte Carlo Tree Search for strategic exploration in the vast reasoning space.
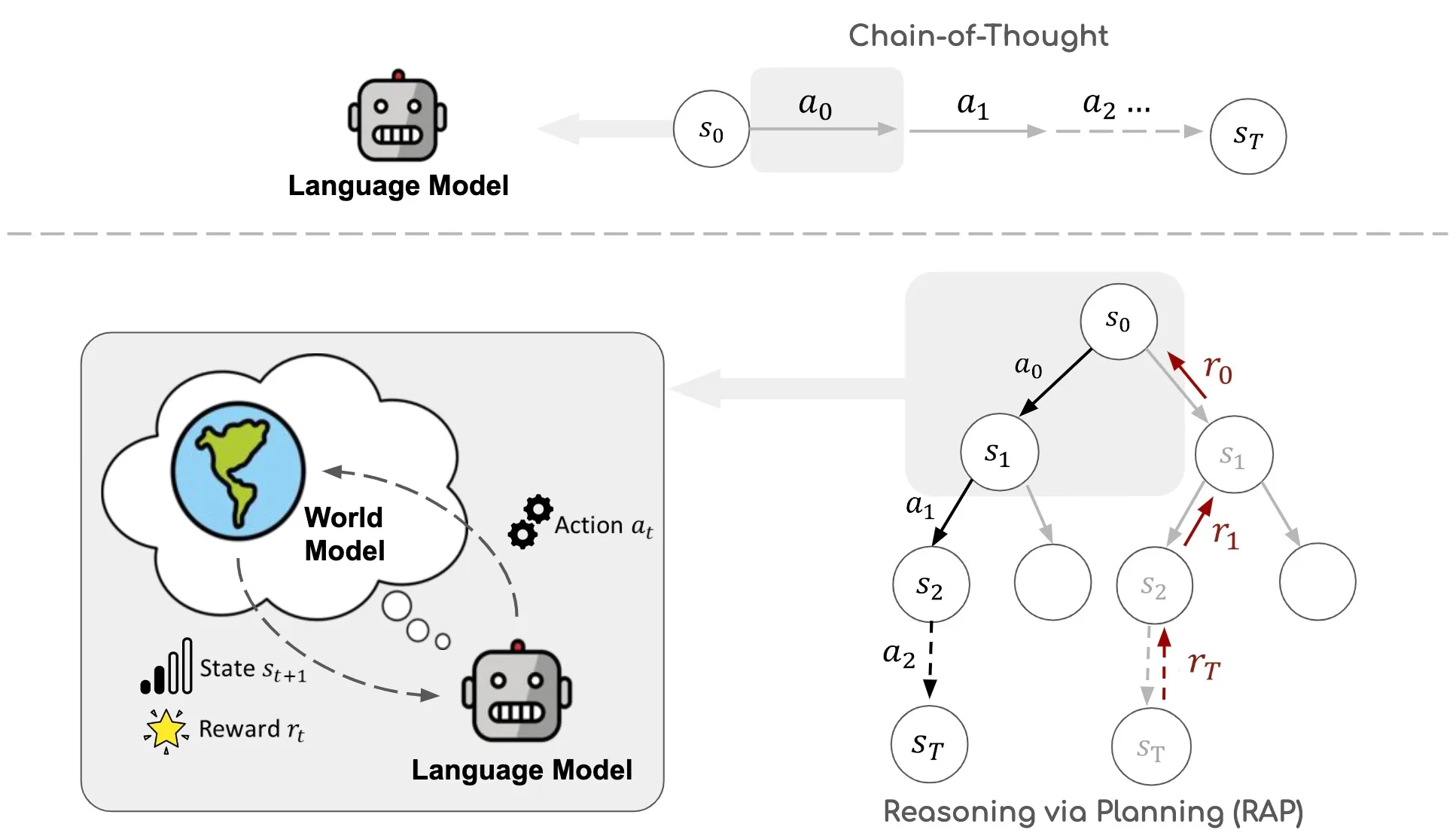
Reasoning via Planning (RAP)
Language Model as World Model
What’s a world model?
In general, a world model predicts the next state of the reasoning after applying an action to the current state. Ha and Schmidhuber, 2018b; Matsuo et al., 2022
RAP defines the state and action in different ways depending on the specific reasoning problems. And thus the reasoning process can be described as a Markov Decision Process (MDP):
Given the initial state , a reasoning agent (LLMs) generates an action space by sampling from its generative distribution , where is a proper prompt (in-context demonstrations). Once an action is chosen, the world model (LLMs) then samples the next state from a state transition distribution given by a transitional model (LLMs), where is another prompt to guide the LLM to generate a state.
What’s difference from Chain-of-Thought (CoT)?
The reasoning trace of CoT only consists of a sequence of actions, while the RAP’s consists of a sequence of interleaved states and actions, leading to a more grounded and coherent inference argued by authors.
Reward Design
A task-specific reward function:
- Likelihood of the action:
- Confidence of the state:
- Self-evaluation by the LLM:
- Task-specific heuristics:
Planning with Monte Carlo Tree Search (MCTS)[1][2][3]
MCTS builds a reasoning tree iteratively, where each node represents a state, and each edge represents an action and the transition from the current state to the next state after applying the action. And to guide the reasoning agent to expand and explore the most promising nodes of the tree, MCTS maintains a state-action value function , where estimates the expected future reward of taking action in state .
The four phases in an iteration in MCTS planning:
- Selection:
- Expansion:
- Simulation:
- Back-propagation:
Experiments
- Plan Generation on Blocksworld:
Reflection
- General reward design is required for General reasoning framework (i.e., task-agnostic).